
Ez egy réges-régi történet:
A Firefox régóta hírhedt arról, hogy túl sok memóriát használ. Ennek a hírnévnek a valóságtartalma az évek során változott, de a böngészővel kapcsolatban ez a közvélekedés megmaradt. Az elmúlt esztendőkben minden egyes Firefox-kiadást a szkeptikus felhasználók azzal a kérdéssel fogadták, hogy „kijavították már a memóriaszivárgást?". A Firefox 4 2011 márciusában lett kiadva egy hosszú béta-ciklust és többszöri elhalasztott szállítási dátumot követően - és ugyanezek a kérdések fogadták az új kiadást. Míg a Firefox 4 jelentős előrelépést jelentett a web számára olyan területeken, mint a nyílt videó, a JavaScript teljesítménye és a gyorsított grafika, addig sajnos jelentős visszalépést jelentett a memóriahasználat terén.
A webböngészők terén az elmúlt években nagy verseny alakult ki. A mobileszközök térhódításával, a Google Chrome megjelenésével és a Microsoft webbe történő újrabefektetésével a Firefoxnak számos kiváló és jól finanszírozott versenytárssal kellett megküzdenie a haldokló Internet Explorer helyett. A Google Chrome különösen sokat tett azért, hogy gyors és kecses böngészési élményt nyújtson. A nehezebb úton kezdtük megtanulni, hogy jó böngészőnek lenni már nem elegendő - kiváló böngészőnek kell lennünk. Ahogy Mike Shaver, a Mozilla akkori műszaki alelnöke és a Mozilla régi munkatársa mondta: „ez az a világ, amit akartunk, és ez az a világ, amit létrehoztunk".
Így álltunk 2011 elején. A Firefox piaci részesedése stagnált vagy csökkent, míg a Google Chrome gyorsan emelkedett. Bár a teljesítmény tekintetében kezdtünk felzárkózni, a memóriafogyasztás tekintetében még mindig jelentős versenyhátrányban voltunk, mivel a Firefox 4 a gyorsabb JavaScriptbe és a gyorsított grafikába fektetett be, gyakran a megnövekedett memóriafogyasztás árán. A Firefox 4 megjelenése után egy Nicholas Nethercote által vezetett mérnökcsoport elindította a MemShrink projektet, hogy a memóriafogyasztást ellenőrzés alá vonja. Ma, közel másfél évvel később, ez az összehangolt erőfeszítés radikálisan megváltoztatta a Firefox memóriafogyasztását és hírnevét. A „memóriaszivárgás" a legtöbb felhasználó fejében már a múlté, és a Firefox gyakran az egyik legvékonyabb böngészőként szerepel az összehasonlításokban. Ebben a fejezetben a Firefox memóriahasználatának javítása érdekében tett erőfeszítéseinket és az út során szerzett tanulságokat vizsgáljuk meg.
A felépítés áttekintése
A Firefox felépítésének és működésének alapvető ismereteire lesz szüksége ahhoz, hogy megértse a felmerült problémákat és az általunk talált megoldásokat.
A modern webböngésző alapvetően egy virtuális gép, amely nem megbízható kód futtatására szolgál. Ez a kód HTML, CSS és JavaScript (JS) kombinációja, amelyet harmadik felek biztosítanak. Emellett a Firefox kiegészítőkből és bővítményekből származó kódot is tartalmaz. A virtuális gép számítási képességeket, a szöveg elrendezését és stílusát, képeket, hálózati hozzáférést, offline tárolást, sőt, még a hardveresen gyorsított grafikához való hozzáférést is biztosítja. E képességek egy része az adott feladatra tervezett API-kon, alkalmazás programozási interfészeken keresztül érhető el; sok más pedig teljesen új felhasználási célokra átdolgozott API-kon keresztül. A web fejlődése miatt a webböngészőknek nagyon liberálisnak kell lenniük abban, hogy mit fogadnak el, és amit a böngészők 15 évvel ezelőtt még úgy terveztek, hogy kezelni tudják, az ma már nem biztos, hogy releváns a nagy teljesítményű élmény biztosításához.
A Firefoxot a Gecko elrendezés (layout) motor és a Spidermonkey JavaScript motor hajtja. Mindkettőt elsősorban a Firefox-hoz fejlesztették, de különálló és egymástól függetlenül újrafelhasználható kódrészletek. Mint minden széles körben használt layout és JavaScript motor, mindkettő C++ nyelven íródott. A Spidermonkey implementálja a JavaScript virtuális gépet, beleértve a szemétgyűjtést (Grabage Collector, azaz GC) és a just-in-time JS kódfordítás (JIT, futattás idejű) többféle változatát. A Gecko valósítja meg a legtöbb, egy weboldalon látható API-t, beleértve a DOM-ot, a grafikus leképzést szoftveres vagy hardveres feldolgozás segítségével, az oldal és a szöveg elrendezését, a teljes hálózati réteget és még sok mást. Ezek együttesen adják azt a platformot, amelyre a Firefox épül. A Firefox felhasználói felülete, beleértve a címsávot és a navigációs gombokat, nem más, mint speciális weboldalak sorozata, amelyek emeltszintű jogosultságokkal futnak. Ezek a jogosultságok mindenféle olyan funkcióhoz hozzáférést biztosítanak számukra, amelyeket a normál weboldalak nem láthatnak. Ezeket a speciális, beépített, kiváltságos oldalakat chrome-nak (krómnak, nem a Google Chrome-ra utalva) nevezzük, szemben a tartalommal, vagyis a normál weboldalakkal.
A mi céljaink szempontjából a Spidermonkey és a Gecko legérdekesebb részletei a memóriakezelésük. A böngésző memóriáját két jellemző alapján kategorizálhatjuk: hogyan történik a memória kiosztása és hogyan szabadul fel. A dinamikusan allokált memóriát (a heap) nagy darabokban kapjuk az operációs rendszertől, és a heap allokátor osztja fel a kért mennyiségekre. Két fő heap allokátor létezik:
- a speciális garbage-collected heap allocator, amelyet a Spidermonkeyben a garbage-collected memóriához (a GC heap) használnak, és
- a jemalloc, amelyet minden más használ a Spidermonkey-ben és a Geckó-ban.
A memória felszabadításának is három módszere van: manuálisan, referenciaszámolással és szemétgyűjtéssel.
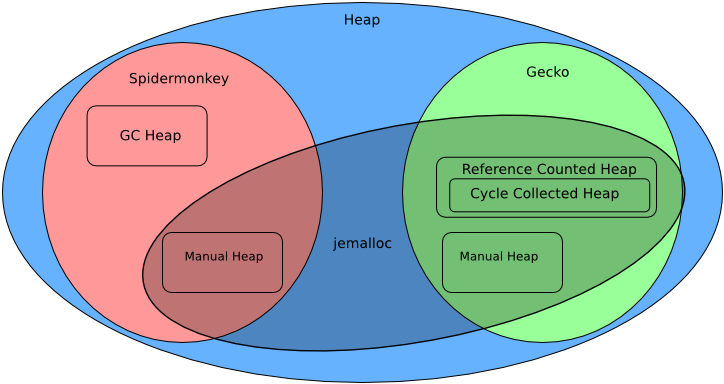
A Spidermonkey GC-heapje tartalmazza az objektumokat, függvényeket és a legtöbb más dolgot, amit a JS futtatása hoz létre. A GC heapben tároljuk a megvalósítási részleteket is, amelyek élettartama ezekhez az objektumokhoz kapcsolódik. Ez a heap egy meglehetősen szabványos inkrementális mark-and-sweep gyűjtőt használ, amelyet erősen optimalizáltunk a teljesítmény és a válaszidő szempontjából. Ez azt jelenti, hogy a szemétgyűjtő időről időre felébred, és megnézi a GC-heap összes memóriáját. Egy „indulókészletből" (mint például az éppen megtekintett oldal globális objektuma) kiindulva „megjelöli" a heap-ben lévő összes elérhető objektumot. Ezután „átfésüli" az összes olyan objektumot, amely nincs megjelölve, és szükség esetén újra felhasználja a memóriát.
A Gecko-ban a memória nagy része referenciaszámlálású. A hivatkozásszámlálással a memória egy adott darabjára történő hivatkozások számát követjük nyomon. Amikor ez a szám eléri a nullát, tehát az objektumra nincsen több hivatkozás, a memória felszabadul. Bár a referenciaszámlálás technikailag a szemétgyűjtés egyik formája, e tárgyalás során megkülönböztetjük a szemétgyűjtési rendszerektől, amelyek speciális kódot (azaz szemétgyűjtőt) igényelnek a memória időszakos felszabadításához, visszanyeréséhez. Az egyszerű hivatkozásszámlálás nem képes kezelni a ciklusokat, amikor A memória egy darabja hivatkozik B memóriára, és fordítva. Ebben a helyzetben mind A, mind B memória hivatkozási száma 1, és soha nem szabadul fel. A Gecko rendelkezik egy speciális nyomkövető szemétgyűjtővel, amely kifejezetten az ilyen ciklusok összegyűjtésére szolgál, és amelyet ciklusgyűjtőnek nevezünk. A ciklusgyűjtő csak bizonyos osztályokat kezel, amelyekről ismert, hogy részt vesznek a ciklusokban, és a ciklusgyűjtést választják, így a ciklusgyűjtő heap-re úgy tekinthetünk, mint a referenciaszámlálású heap egy részhalmazára. A ciklusgyűjtő a Spidermonkey-ben lévő szemétgyűjtővel is együttműködik a nyelvek közötti memóriakezelés kezelésében, így a C++ kód képes JS objektumokra való hivatkozásokat tartani és fordítva.
Mind a Spidermonkey-ben, mind a Gecko-ban rengeteg manuálisan kezelt memória is van. Ez mindent magában foglal a tömbök és hashtáblák belső memóriájától kezdve a kép- és szkript-forrásadatok pufferéig. A manuálisan kezelt memóriára más speciális allokátorok is vannak rétegezve. Ilyen például az aréna allokátor (arena allocato). Az arénákat akkor használják, ha nagyszámú különálló allokációt lehet egyszerre felszabadítani. Az aréna allokátor a memóriatárolókat a fő heap allokátortól szerzi be, és igény szerint felosztja őket. Amikor az arénára már nincs szükség, az aréna visszaadja ezeket a darabokat a fő heap-nek anélkül, hogy a sok kisebb allokációt külön-külön fel kellene szabadítani. A Gecko motor aréna allokátort használ az oldalkiosztási adatokhoz, amelyeket egyszerre lehet kidobni, amikor egy oldalra már nincs szükség. Az aréna kiosztás lehetővé teszi az olyan biztonsági funkciók megvalósítását is, mint például a poisoning (mérgezés, felülírás), ahol felülírjuk a kiosztott memóriát, hogy ne lehessen felhasználni egy kihasználható biztonsági hibában, exploit-ban.
A Firefox kisebb részeiben számos más egyéni memóriakezelő rendszer is létezik, amelyeket különböző okokból használnak, de ezek nem relevánsak a mi tárgyalásunk szempontjából. Most, hogy rövid áttekintést kaptunk a Firefox memóriaarchitektúrájáról, megbeszélhetjük az általunk talált problémákat és azok javítását.
Csak azt látod, amit mérsz
A probléma megoldásának első lépése, hogy kitaláljuk, mi a probléma. A memóriaszivárgás szigorú definíciója - a memória kiosztása az operációs rendszerből (OS), majd nem visszaengedése az OS-nek - nem terjed ki minden olyan helyzetre, amelynek javításában érdekeltek vagyunk. Vannak olyan helyzetek, amelyekkel találkozunk, és amelyek nem tekinthetőek a szigorú értelemben vett „szivárgásoknak":
- Egy adatstruktúra kétszer annyi memóriát igényel, mint amennyire szüksége lenne.
- A már nem használt memória nem szabadul fel, amíg egy időzítő le nem jár.
- Ugyanannak a nagy puffernek (karakterláncok, képadatok stb.) több példánya létezik a programban.
Mindezt tovább bonyolítja az a tény, hogy a Firefox heap-en lévő memória nagy része valamilyen szemétgyűjtésnek (Garbage Collection - GC) van alávetve, így a már nem használt memória csak a GC következő futtatásakor szabadul fel. A „szivárgás" kifejezést nagyon lazán használjuk minden olyan helyzetre, amely azt eredményezi, hogy a Firefox kevésbé hatékony a memóriahasználatban, mint amennyire ésszerű lenne. Ez összhangban van azzal, ahogyan a felhasználóink is használják a kifejezést: a legtöbb felhasználó és még a webfejlesztők sem tudják megmondani, hogy a magas memóriahasználat valódi szivárgás vagy a böngészőben működő számos más tényező miatt van-e.
A MemShrink indulásakor nem sok rálátásunk volt a böngésző memóriahasználatára. A memóriaproblémák természetének azonosításához gyakran olyan összetett eszközökre volt szükség, mint a Massif, vagy alacsonyabb szintű eszközökre, mint a GDB. Ezeknek az eszközöknek számos hátrányuk van:
- Fejlesztők számára készültek, és nem könnyű használni őket.
- Nem ismerik a Firefox belső tulajdonságait (például a különböző adatstruktúrák megvalósításának részleteit).
- Nem „mindig be vannak kapcsolva" - akkor kell használni őket, amikor a probléma felmerül.
Ezekért a hátrányokért cserébe nagyon hatékony eszközöket kapunk. Ezen hátrányok kezelésére idővel egy sor egyedi eszközt építettünk, hogy kevesebb munkával nagyobb betekintést nyerjünk a böngésző viselkedésébe.
Az első ilyen eszköz a about:memory. Először a Firefox 3.6-ban vezették be, és eredetileg egyszerű statisztikákat mutatott a heap-ről, például a leképezett és lekötött memória mennyiségét. Később néhány, az egyes fejlesztők számára érdekes dologra vonatkozó mérésekkel egészült ki, például a beágyazott SQLite adatbázis-motor által használt memóriával és a hardveresen gyorsított grafikus alrendszer által használt memória mennyiségével. Ezeket a méréseket memória reportereknek nevezzük. Ezektől az egyszeri kiegészítésektől eltekintve a about:memory egy kezdetleges eszköz maradt, amely néhány összefoglaló statisztikát mutatott be a memóriahasználatról. A legtöbb lefoglalt memóriatípus nem rendelkezett memória reporterrel, és nem volt külön számon tartva a about:memory oldalon. Ennek ellenére az about:memory oldalt bárki használhatja speciális eszköz vagy Firefox-építés (build) nélkül is, csak be kell írni a böngésző címsorába. Ez lenne a "gyilkos funkció".
Miközben hozzáadtuk ezt a memória típus jelentést a about:memory-hez, rájöttünk, hogy a hasonló jelentés más memóriafoglalásokhoz is lehetővé tenné a hasznos heap-profilozást olyan speciális eszközök nélkül, mint a Massif. A about:memory-t úgy módosítottuk, hogy egy sor összefoglaló statisztika helyett egy fát jelenítsen meg, amely a memóriahasználatot nagyszámú különböző felhasználási módra bontja. Ezután elkezdtük hozzáadni a riportereket más típusú nagy heap-kiosztásokhoz, például a layout alrendszerhez. Az egyik legkorábbi, metrikák által vezérelt törekvésünk a memória reporter által nem lefedett, nem osztályozott memória mennyiségének csökkentése volt. Választottunk egy eléggé önkényes számot, a teljes halom 10%-át, és azt tűztük ki célul, hogy átlagos használati forgatókönyvek esetén a nem titkosított memória mennyisége erre az értékre csökkenjen. Végül kiderült, hogy a 10% túl alacsony szám volt ahhoz, hogy elérjük. Egyszerűen túl sok kis egyszeri allokáció van a böngészőben ahhoz, hogy a heap-unclassified (besorolás nélküli) megbízhatóan 15% alá csökkenjen. A heap-unclassified mennyiségének csökkentése növeli a betekintést abba, hogy a böngésző hogyan használja a memóriát.
A heap-unclassified mennyiségének csökkentése érdekében írtunk egy eszközt, a Dark Matter Detector (DMD) névre keresztelt eszközt, amely segít a besorolás nélküli heap-kiosztások felkutatásában. Az eszköz úgy működik, hogy a heap allokátor helyett beilleszti magát az about:memory jelentéskészítési folyamatba, és a bejelentett memóriablokkokat összeveti az allokált blokkokkal. Ezután híváshelyenként összesíti a nem bejelentett memóriafoglalásokat. A DMD futtatása egy Firefox-munkameneten a heap-unclassifiedért felelős hívóhelyek listáját eredményezi. Miután azonosítottuk a kiosztások forrását, a felelős komponens megtalálása és egy fejlesztő hozzáadása a memóriajelentőhöz gyorsan ment. Néhány hónapon belül volt egy olyan eszközünk, amely olyan dolgokat tudott mondani, mint például „a böngésződ összes Facebook-oldala 250 MB memóriát használ, és itt van a memória felhasználásának bontása".
Egy másik eszközt is kifejlesztettünk (Measure and Save néven) a memóriaproblémák hibakeresésére, ha már azonosítottuk őket. Ez az eszköz mind a JS-heap, mind a ciklusosan gyűjtött C++-heap reprezentációit kiírja egy fájlba. Ezután írtunk egy sor elemző szkriptet, amelyek képesek bejárni a kombinált heapet, és megválaszolni olyan kérdéseket, mint például „mi tartja életben ezt az objektumot?" (ami miatt nem lehet eltávolítani a memóriából). Ez sok hasznos hibakeresési technikát tett lehetővé, kezdve a heapgráf egyszerű vizsgálatától az olyan kapcsolatok kereséséig, amelyeknek meg kellett volna szakadniuk, egészen a debuggerbe való belépésig és a töréspontok beállításáig az egyes érdekes, vizsgált objektumokon.
Ezeknek az eszközöknek az egyik fő előnye, hogy - ellentétben egy olyan eszközzel, mint a Massif - várhatunk, amíg a probléma megjelenik, mielőtt használnánk az eszközt. Sok heap-profilozót (beleértve a Massif-et is) a program indításakor kell elindítani, nem pedig a probléma megjelenése után egy kicsivel. Egy másik előnye ezeknek az újjonnan kifejlesztett eszközöknek, hogy az információ elemezhető és felhasználható anélkül, hogy a probléma reprodukálódna előttünk. Együtt lehetővé teszik a felhasználók számára, hogy információt rögzítsenek az általuk észlelt problémára vonatkozóan, és elküldjék a fejlesztőknek, ha azok nem tudják reprodukálni a problémát. Egy webböngésző felhasználóitól, még azoktól is, akik elég kifinomultak ahhoz, hogy hibákat írjanak be egy hibakövetőbe, általában túl nagy kérés elvárni, hogy a GDB-t vagy a Massifet használják a böngészőben. De az about:memory eszköz betöltése vagy egy kis JavaScript-töredék futtatása a hibajelentéshez csatolandó adatok megszerzéséhez sokkal kevésbé nehéz feladat. Az általános heapprofilerek sok információt rögzítenek, de sok költséggel járnak. Sikerült egy olyan, a saját igényeinkre szabott eszközkészletet írnunk, amely jelentős előnyöket nyújtott számunkra az általános eszközökkel szemben.
Nem mindig érdemes egyéni eszközökbe fektetni; nem véletlenül használjuk a GDB-t ahelyett, hogy minden egyes szoftverhez új hibakereső programot írnánk. De azokban a helyzetekben, amikor a meglévő eszközök nem tudják a kívánt módon biztosítani a szükséges információkat, úgy találtuk, hogy az egyedi eszközkészítés nagy nyereség lehet. Körülbelül egy évnyi részmunkaidős munkába telt az about:memory, mire eljutottunk arra a pontra, amikor már befejezettnek tekintettük. Még ma is folyamatosan új funkciókat és riportereket adunk hozzá, ha szükséges. Az egyedi eszközök jelentős beruházást jelentenek. A téma részletes taglalása meghaladja e fejezet kereteit, de az egyéni eszközök megírása előtt alaposan mérlegelje az előnyöket és a költségeket.
Könnyen elérhető gyümölcsök
Az általunk készített eszközökkel a korábbinál jóval nagyobb rálátást kaptunk a böngésző memóriahasználatára. Miután egy ideig használtuk őket, kezdtünk ráérezni arra, hogy mi a normális és mi nem. A nem normális, esetleg hibás dolgok kiszűrése nagyon könnyűvé vált. A nagy mennyiségű heap-unclassified olyan titkos webes funkciók használatára utalt, amelyekhez még nem adtunk memória reportereket, vagy a Gecko belső rendszereinek szivárgásaira. A JS-motor furcsa helyein lévő nagy memóriahasználat jelezhette, hogy a kód valamilyen optimalizálatlan vagy zombi esetet érintett. Ezt az információt arra tudtuk használni, hogy felkutassuk és kijavítsuk a Firefox legrosszabb hibáit.
Az egyik anomália, amit már korán észrevettünk, az volt, hogy néha egy tároló (compartment) egy már bezárt oldalhoz ragadt, még akkor is, ha a szemétgyűjtőt többszöri futtatásra kényszerítettük. Néha ezek a tárolók végül maguktól eltűntek, néha pedig a végtelenségig fennmaradtak. Ezeket a szivárgásokat zombi tárolónak neveztük el. Ezek voltak a legsúlyosabb szivárgások, mivel a weblapok által felhasználható memória mennyisége korlátlan. Számos ilyen hibát kijavítottunk mind a Gecko, mind a Firefox felhasználói felületének kódjában, de hamarosan kiderült, hogy a zombi tárolók legnagyobb forrása a bővítményektől ered. A bővítmények szivárgásainak kezelése több hónapig megakasztott minket, mire megtaláltuk a megoldást, amelyet a fejezet későbbi részében tárgyalunk. A legtöbb ilyen zombi tárolót mind a Firefox-ban, mind a kiegészítőkben a hosszú életű JS objektumok okozták, amelyek rövid életű JS objektumokra való hivatkozásokat tartottak fenn. A hosszú életű JS-objektumok jellemzően a böngészőablakhoz csatolt objektumok, vagy akár globális singletonok, míg a rövid életű JS-objektumok weboldalak objektumai lehetnek.
A DOM és a JS működésének módja miatt egy weboldal egyetlen objektumára való hivatkozás életben tartja az egész oldalt és annak globális objektumát (és mindent, ami onnan elérhető). Ez könnyen több megabájtnyi memóriát jelenthet. A szemétgyűjtő rendszer egyik finomabb aspektusa, hogy a GC csak akkor követeli vissza a memóriát, amikor az elérhetetlenné válik, nem pedig akkor, amikor a program befejezte annak használatát. A programozó feladata, hogy biztosítsa, hogy az olyan memória, amelyet nem fog újra használni, program számára elérhetetlen legyen, felszabadításra kerüljön. Ha nem sikerül eltávolítani az összes hivatkozást egy objektumra, az még súlyosabb következményekkel jár, ha a hivatkozó és a hivatkozott objektum élettartama várhatóan jelentősen eltér egymástól. A viszonylag gyorsan visszanyerhető memória (például egy weboldal által használt memória) ehelyett a hosszabb élettartamú hivatkozó objektum (például a böngészőablak vagy maga az alkalmazás) élettartamához van kötve.
A JS-heap töredezettsége szintén hasonló okból okozott problémát számunkra. Gyakran tapasztaltuk, hogy a sok weboldal bezárása nem eredményezte a Firefox operációs rendszer által jelentett memóriahasználatának jelentős csökkenését. A JS-motor megabájt méretű darabokban osztja ki a memóriát az operációs rendszerből, és ezt a darabot szükség szerint felosztja a különböző rekeszek között. Ezeket a darabokat csak akkor lehet visszaadni az operációs rendszernek, ha teljesen kihasználatlanok. Azt tapasztaltuk, hogy az új darabok kiosztását szinte mindig az okozta, hogy a webes tartalom több memóriát igényelt, de az utolsó dolog, ami megakadályozta egy darab felszabadítását, gyakran egy a böngésző részét képző (chrome compartment) tároló volt. Néhány hosszú élettartamú objektum keveredése egy rövid élettartamú objektumokkal teli memóriaszakszban megakadályozta, hogy a weboldalak bezárásakor visszaszerezzük az adott memóriaszakaszt. Ezt úgy oldottuk meg, hogy szétválasztottuk a böngésző részeket (crome) és a weboldal tartalom rekeszeket, így bármelyik darabhoz vagy chrome, vagy tartalom helyfoglalás tartozik. Ez jelentősen megnövelte a memória mennyiségét, amelyet vissza tudtunk adni az operációs rendszernek a lapok bezárásakor.
Felfedeztünk egy másik problémát, amelyet részben a töredezettség csökkentésére szolgáló technika okozott. A Firefox elsődleges heap-allokátorának a jemalloc egy Windows és Mac OS X rendszerekre módosított változata. A jemalloc célja, hogy csökkentse a töredezettség miatti memóriaveszteséget. Az egyik technika, amelyet ehhez használ, az allokációk különböző méretosztályokra való felkerekítése, majd ezen méretosztályok egybefüggő memóriaegységekben történő allokálása. Ez biztosítja, hogy a felszabaduló hely később újra felhasználható legyen egy hasonló méretű kiosztáshoz. A kerekítés némi helypazarlással is jár. Ezt az elpazarolt helyet nevezzük slop-nak. A legrosszabb esetben bizonyos méretosztályok esetében a kiosztott hely közel 50%-át elpazarolhatjuk. A jemalloc méretosztályok felépítése miatt ez általában közvetlenül egy kettes hatvány átadása után történik (például: a 17-et 32-re kerekít, 1025-öt pedig 2048-ra kerekíti).
Gyakran előfordul, hogy a memória kiosztásakor nincs sok választási lehetőség a kért mennyiséget illetően. Egy osztály új példányának allokációjához plusz bájtokat hozzáadni általában hasznos. Máskor viszont van némi rugalmasságunk. Ha egy karakterlánc számára osztunk ki helyet, akkor extra helyet használhatunk, hogy elkerüljük a puffer újbóli kiosztását, ha később a karakterláncot hozzácsatoljuk. Amikor ez a rugalmasságra igény mutatkozik, akkor van értelme olyan mennyiséget kérni, amely pontosan megfelel egy méretosztálynak. Így az a memória, ami egyébként slopként „elpazarolt" volna, extra költség nélkül felhasználható. Általában a kódot úgy írjuk, hogy kettes hatványokat kérünk, mert ezek szépen illeszkednek szinte minden valaha írt allokátorba, és nem igényelnek speciális ismereteket az allokátorról.
Rengeteg olyan kódot találtunk a Geckóban, amelyet úgy írtak, hogy kihasználja ezt a technikát, és több olyan helyet is, ahol megpróbálták, de rosszul csinálták. Több kódrészlet is megpróbált egy szép kerek memóriadarabot kiosztani, de a matematikát kissé elrontotta, és végül a tervezettnél kicsit több memóriát osztott ki. A jemalloc méretosztályainak felépítése miatt ez gyakran ahhoz vezetett, hogy a kiosztott hely közel 50%-át elvesztegették slop-ként. Az egyik különösen kirívó példa egy aréna allokátor implementációjában volt, amelyet elrendezési adatstruktúrákhoz használtak. Az aréna 4 KB-os darabokat próbált kinyerni a heap-ből. Könyvelési célokból néhány szót is hozzátoldott, ami azt eredményezte, hogy valamivel több mint 4 KB-ot kért, amit 8 KB-ra kerekített. Ennek a hibának a kijavítása csak a GMail esetében több mint 3 MB-ot takarított meg. Egy különösen nehéz elrendezésű tesztesetnél ez több mint 700 MB memóriát takarított meg, és a böngésző teljes memóriafogyasztását 2 GB-ról 1,3 GB-ra csökkentette.
Hasonló problémával találkoztunk az SQLite esetében is. A Gecko az SQLite-ot használja adatbázis-motorként az olyan funkciókhoz, mint az előzmények és a könyvjelzők. Az SQLite úgy van megírva, hogy a beágyazó alkalmazásnak nagyfokú kontrollt adjon a memória kiosztása felett, és nagyon aprólékosan méri a saját memóriahasználatát. Ahhoz, hogy ezeket a méréseket megtartsa, hozzáad néhány szót (words), ami a kiosztást a következő méretosztályba tolja. Ironikus módon a memóriafogyasztás nyomon követéséhez szükséges műszerezés végül megduplázza a fogyasztást, miközben jelentős aluljelentést okoz. Az ilyen típusú hibákat „bohóccipőnek" nevezzük, mert egyszerre komikusan rosszak és sok elpazarolt üres helyet eredményeznek, akárcsak egy bohóc cipője.
Attól még hogy nem a te hibád, nem jelenti azt, hogy nem a te problémád
Több hónap alatt nagy előrelépéseket tettünk a Firefox memóriafogyasztásának javításában és a szivárgások kijavításában. Azonban nem minden felhasználó látta ennek a munkának az előnyeit. Világossá vált, hogy a felhasználóink által tapasztalt memóriaproblémák jelentős része a kiegészítőkből eredt. A szivárgásveszélyes bővítményekkel kapcsolatos hibakövetésünk végül több mint 100 megerősített jelentést tartalmazott szivárgást okozó bővítményekről.
Történelmileg a Mozilla megpróbálta mindkét lehetőséget kihasználni a kiegészítőkkel kapcsolatban. A Firefoxot bővíthető böngészőként, bővítmények gazdag választékával forgalmazzuk. Amikor azonban a felhasználók teljesítményproblémákat jelentettek a bővítményekkel kapcsolatban, egyszerűen azt mondtuk a felhasználóknak, hogy ne használják őket. A memóriaszivárgást okozó bővítmények száma miatt ez a helyzet tarthatatlanná vált. Sok Firefox-kiegészítőt a Mozilla addons.mozilla.org (AMO) oldalon keresztül terjesztenek. Az AMO-nak felülvizsgálati irányelvei vannak, amelyek célja, hogy a bővítményekben előforduló gyakori problémákat felismerjék. Akkor kezdtünk képet kapni a probléma kiterjedéséről, amikor az AMO felülvizsgálói elkezdték tesztelni a bővítményeket memóriaszivárgások szempontjából olyan eszközökkel, mint az about:memory. Számos tesztelt bővítményről kiderült, hogy olyan problémákkal küzd, mint például a zombi rekeszek. Elkezdtük megkeresni a bővítmény-szerzőket, és összeállítottunk egy listát a legjobb gyakorlatokról és a szivárgást okozó gyakori hibákról. Sajnos ez meglehetősen korlátozott sikerrel járt. Bár néhány kiegészítőt a szerzők kijavítottak, a legtöbbet nem.
Számos oka volt annak, hogy ez hatástalannak bizonyult. Nem minden bővítményt frissítenek rendszeresen. A kiegészítők szerzői önkéntesek, akiknek saját időbeosztásuk és prioritásaik vannak. A memóriaszivárgások elhárítása nehéz lehet, különösen akkor, ha a probléma nem reprodukálható. A korábban ismertetett heap gyűjtő eszköz nagyon hatékony, és megkönnyíti az információgyűjtést, de a kimenet elemzése még mindig bonyolult, és túl sok feladatot várhatunk el a kiegészítő szerzőktől. Végül, nem voltak erős ösztönzők a szivárgások kijavítására. Senki sem akar rossz szoftvert szállítani, de nem lehet mindig mindent kijavítani. Az embereket talán jobban érdekli az is, hogy azt tegyék, amit ők akarnak, mint azt, amit mi akarunk, hogy tegyenek.
Sokáig beszéltünk arról, hogy ösztönzőket kell teremteni a szivárgások kijavítására. A bővítmények más teljesítményproblémákat is okoztak a Mozilla számára, ezért tárgyaltunk arról, hogy a bővítmények teljesítményadatait láthatóvá tegyük az AMO-ban vagy magában a Firefoxban. Az elmélet az volt, hogy ha tájékoztatni tudnánk a felhasználókat a telepített vagy telepíteni kívánt bővítmények teljesítményre gyakorolt hatásairól, az segítene nekik abban, hogy megalapozott döntéseket hozzanak a használt bővítményekkel kapcsolatban. Az első probléma ezzel kapcsolatban az, hogy az olyan fogyasztói szoftverek, mint a webböngészők felhasználói általában nem képesek megalapozott döntéseket hozni az ilyen kompromisszumokkal kapcsolatban. Vajon a Firefox 400 millió felhasználója közül hányan értik, hogy mi az a memóriaszivárgás, és tudják felmérni, hogy megéri-e elszenvedni azt azért, hogy használhassanak egy tetszőleges kiegészítőt? Másodszor, a bővítmények teljesítményre gyakorolt hatásainak ilyen módon történő kezeléséhez a Mozilla közösség számos különböző részének beleegyezésére volt szükség. A kiegészítőket készítő közösséget alkotó emberek például nem voltak elragadtatva attól az ötlettől, hogy a kiegészítőket tiltással sújtsák. Végül a Firefox bővítmények nagy százalékát egyáltalán nem az AMO-n keresztül telepítik, hanem más szoftverekkel együtt. Nagyon kevés befolyásunk van ezekre a kiegészítőkre, hacsak nem próbáljuk meg letiltani őket. Ezen okok miatt felhagytunk az ilyen ösztönzők létrehozására tett kísérleteinkkel.
A másik ok, amiért lemondtunk arról, hogy ösztönözzük a bővítményeket a szivárgások kijavítására, az az, hogy teljesen más megoldást találtunk a probléma megoldására. Végül sikerült megtalálnunk a módját annak, hogy „megtisztítsuk" a Firefoxban a szivárgó bővítményeket. Sokáig nem gondoltuk, hogy ez megvalósítható lenne anélkül, hogy sok kiegészítő tönkremenne, de ennek ellenére tovább kísérleteztünk vele. Végül sikerült egy olyan technikát megvalósítanunk, amely visszanyerte a memóriát anélkül, hogy a legtöbb bővítményt hátrányosan befolyásolta volna. Kihasználtuk a memóriatárolók közötti határokat, hogy „levágjuk" a hivatkozásokat a chrome tárolók (a böngésző része) a tartalmi tárolókba, amikor az oldalra navigálunk vagy a lapot bezárjuk. Ezáltal egy objektum marad a chrome tárolóban, amely már nem hivatkozik semmire. Eredetileg azt gondoltuk, hogy ez problémát jelent, amikor a kód megpróbálja használni ezeket az objektumokat, de azt találtuk, hogy a legtöbbször ezeket az objektumokat később nem használják. Valójában a bővítmények véletlenül és értelmetlenül gyorsítótáraznak dolgokat a weboldalakról, és az utánuk való automatikus takarításnak nem sok hátránya volt. Egy technikai problémára kerestünk társadalmi megoldást.
Az örök kitartás a kiválóság ára
A MemShrink projekt jelentős előrelépést ért el a Firefox memóriaproblémáival kapcsolatban, de még sok munka vár ránk. A legtöbb egyszerű problémát már kijavították - ami még hátravan, az jelentős mennyiségű mérnöki munkát igényel. Terveink között szerepel a JS heap töredezettségének további csökkentése egy mozgó garbage collector-ral, amely képes konszolidálni a heapet. Átdolgozzuk a képek kezelésének módját, hogy hatékonyabb legyen a memóriafelhasználás. Ellentétben sok befejezett változtatással, ezek komplex alrendszerek átfogó refaktorálását igénylik.
Ugyanilyen fontos, hogy ne lépjünk vissza a már elvégzett fejlesztésekhez. A Mozilla 2006 óta erős kultúrája van a regressziós tesztelésnek. Ahogy a Firefox memóriahasználatának karcsúsításában előrehaladtunk, úgy nőtt meg bennünk az igény a memóriahasználat regressziós tesztelési rendszerére. A teljesítmény tesztelése nehezebb, mint a funkciók tesztelése. A rendszer kiépítésének legnehezebb része az volt, hogy reális munkaterhelést találjunk a böngésző számára. A böngészők meglévő memóriatesztjei elég látványosan elbuktak a realizmus tekintetében. A MemBuster például minden alkalommal gyors egymásutánban számos wikit és blogot tölt be egy új böngészőablakba. A legtöbb felhasználó manapság új ablakok helyett lapokat használ, és a wikiknél és blogoknál összetettebb dolgokat böngészik. Más összehasonlító tesztek az összes oldalt ugyanabba a fülbe töltik be, ami szintén teljesen irreális egy modern webböngésző esetében. Mi egy olyan munkaterhelést dolgoztunk ki, amely véleményünk szerint észszerűen reális. Ez 100 oldalt tölt be egy 30 lapból álló, fixen meghatározott lapkészletbe, a betöltések közötti késleltetéssel, hogy megközelítse az oldalt olvasó felhasználót. A felhasznált oldalak a Mozilla meglévő Tp5 lapkészletéből származnak. A Tp5 az Alexa Top 100-as listáján szereplő oldalakból áll, amelyeket a meglévő teljesítménytesztelési infrastruktúránkban az oldalletöltés teljesítményének tesztelésére használunk. Ez a munkaterhelés hasznosnak bizonyult tesztelési céljainkhoz.
A tesztelés másik szempontja annak kitalálása, hogy mit mérjünk. Tesztrendszerünk a tesztfuttatás során három különböző ponton méri a memóriafogyasztást: mielőtt bármilyen oldalt betöltünk, az összes oldal betöltése után és az összes lap bezárása után. Minden egyes ponton méréseket végzünk 30 másodperces aktivitás nélküli időszak után és a szemétgyűjtő futtatásának kikényszerítése után is. Ezek a mérések segítenek annak megállapításában, hogy a múltban tapasztalt problémák megismétlődnek-e. Ha például jelentős különbség van a +30 másodperces mérés és a szemétgyűjtés kikényszerítése utáni mérés között, az arra utalhat, hogy a szemétgyűjtési heurisztikánk túl konzervatív. Ha jelentős különbség van a bárminemű betöltés előtti és az összes lap bezárása utáni mérés között, az azt jelezheti, hogy memóriaszivárgást tapasztalunk. Mindezen pontokon számos mennyiséget mérünk, beleértve a rezidens készlet méretét, az "explicit" méretet (a malloc(), mmap() stb. segítségével kért memória mennyiségét), és a memória mennyiségét, amely az about:memory bizonyos kategóriáiba tartozik, mint például a heap-unclassified.
Miután összeállítottuk ezt a rendszert, beállítottuk, hogy rendszeresen fusson a Firefox legújabb fejlesztői verzióin. A Firefox korábbi verzióin is lefuttattuk, nagyjából a Firefox 4-ig visszamenőleg. Az eredmény egy pszeudo-folytonos integráció, gazdag historikus adatokkal. Némi szép webfejlesztői munkával létrehoztuk az areweslimyet.com-ot, egy nyilvános webes felületet a memóriatesztelési infrastruktúránk által gyűjtött összes adathoz. Az areweslimyet.com elkészülte óta számos regressziót észlelt, amelyeket a böngésző különböző részein végzett munka okozott. Az areweslimyet.com oldalt felváltotta az https://treeherder.mozilla.org/perfherder/graphs címen elérhető oldal, amely a Mozilla különféle eszközeit gyűjti össze ebben a Perfherder nevű jelentéskészítő eszközben.
A Perfherder az egyik elsődleges eszköz, amelyet a teljesítményseriffek a regressziós (és javítási) riasztások osztályozására és kivizsgálására használnak. Emellett kulcsfontosságú része annak a munkafolyamatnak, amelyet a Firefox-mérnök végeznek, amikor a teljesítmény javításán dolgoznak, akár egy regresszióra reagálva, akár proaktívan mérve a változtatások hatását.
Az Perfherder oldalon „Add test data” gombra kattintva ki kell választani az „awsy” lehetőséget, majd a többi lehetőség közül és a tesztek közül választva elkészülnek a kért diagramok. Választhat más összevetéseket is, például a böngésző teljesítményét mérő „Raptor” teszteredmények közül. A Raptor egy teljesítménytesztelő keretrendszer a böngésző oldalletöltési és böngésző teljesítménymérő tesztek futtatásához. A Raptor több böngészővel kompatibilis, és jelenleg a Firefox Desktop, Firefox Android GeckoView, Fenix, referencia böngészőn, Chromium és Chrome böngészőkön fut.
Az első teljesítménytesztelő keretrendszerünk a Talos, amelyet 2007-ben készítettünk. Ez egy fantasztikus eszköz, amelyet még ma is használnak a Firefox nagyon speciális aspektusainak teljesítménytesztelésére. Jelenleg 45 különböző teljesítménytesztünk van a Talos-ban, és ezek együttesen 462 mérőszámot eredményeznek. Mindezek után maguknak a teszteknek a karbantartása is kihívást jelent, mivel néhányan azok közül, akik eredetileg létrehozták őket, már nem a Mozillánál dolgoznak. Ezeknek a teszteknek a karbantartója általában az a személy lesz, aki utoljára nyúlt a kódhoz, és aki még mindig a közelben van. Mivel azonban magukról a tesztekről nincs dokumentáció, ez nehéz feladattá válik, ha figyelembe vesszük annak lehetőségét, hogy egy módosítás változást okozhat abban, amit mérnek, és teszt eltávolodhat az eredeti céljától.
Idővel egy másik teljesítménytesztelő keretrendszert építettünk, a Raptor-t, amelyet elsősorban az oldalletöltés tesztelésére (példul: az első oldalrajzolás és az első tartalmi rajzolás mérésére) használunk. Ezt a keretrendszert sokkal egyszerűbb karbantartani és a céljának megfelelően tartani, de a tesztekhez használt beállítások elég gyakran változnak ahhoz, hogy könnyen elfelejtsük, hogyan állítottuk be a tesztet, vagy hogy pontosan milyen oldalakat tesztelünk. Van még pár másik keretrendszerünk is, a legújabb (ami még fejlesztés alatt áll) a MozPerftest - erről talán lesz egy blogbejegyzés a jövőben. Ennyi keretrendszer és teszt mellett könnyű belátni, hogy a tesztek karbantartása hosszú távon hogyan válhat egy kis zűrzavarba, ha nem ellenőrzött folyamatról van szó.
Ennek a problémának a megoldására úgy döntöttünk, hogy egy olyan eszközt hozunk létre, amely dinamikusan dokumentálja az összes meglévő teljesítménytesztünket egyetlen felületen, ugyanakkor képes megakadályozni, hogy új teszteket adjunk hozzá megfelelő dokumentáció vagy legalábbis a teszt létezésének elismerése nélkül. Ezt az eszközt PerfDocs-nak neveztük el.
Közösség
A MemShrink erőfeszítéseinek sikeréhez hozzájárult a szélesebb Mozilla-közösség támogatása is. Míg a Firefoxon dolgozó mérnökök többsége (de természetesen nem az összes) a Mozilla alkalmazásában áll, a Mozilla élénk önkéntes közössége tesztelés, lokalizáció, minőségbiztosítás, marketing és egyéb formában nyújt támogatást, ami nélkül a Mozilla projekt megállna. A MemShrinket szándékosan úgy építettük fel, hogy a közösség támogatását megkapjuk, és ez jelentősen megtérült. A MemShrink alapcsapata egy maroknyi fizetett mérnökből állt, de a közösségtől a hibabejelentések, tesztelések és kiegészítések javításán keresztül kapott támogatás felnagyította erőfeszítéseinket.
A memóriahasználat még a Mozilla közösségen belül is régóta frusztráció forrása. Néhányan első kézből tapasztalták a problémákat. Másoknak vannak barátai vagy családtagjai, akik látták a problémákat. Azok, akik elég szerencsések ahhoz, hogy ezt elkerüljék, kétségtelenül láttak panaszokat a Firefox memóriahasználatáról, vagy olyan megjegyzéseket, hogy "javították már a szivárgást?" az új kiadásokhoz, amelyeken keményen dolgoztak. Senki sem élvezi, ha a kemény munkáját kritizálják, különösen, ha ez olyan dolgok miatt történik, amelyeken nem maga dolgozik. Egy olyan régóta fennálló probléma kezelése, amellyel a közösség legtöbb tagja azonosulni tud, kiváló első lépés volt a támogatás kiépítése felé.
Azt mondani, hogy meg fogjuk javítani a dolgokat azonban nem volt elég. Meg kellett mutatnunk, hogy komolyan gondoljuk a dolgok megoldását, és valódi előrelépést tudunk tenni a problémák megoldásában. Heti rendszerességgel nyilvános találkozókat tartottunk a hibajelentések elbírálására és a projektek megvitatására, amelyeken dolgoztunk. Nicholas minden egyes találkozóról blogot is írt, hogy azok is láthassák, mit csinálunk, akik nem voltak ott. Az elvégzett fejlesztések, a hibák számának változása és az új hibák beadása világosan mutatta, hogy milyen erőfeszítéseket tettünk a MemShrink-ért. És a korai fejlesztések, amelyeket a könnyen elérhető gyümölcsökből tudtunk kihozni, nagyban hozzájárultak ahhoz, hogy megmutassuk, hogy meg tudjuk oldani ezeket a problémákat.
Az utolsó lépés az volt, hogy bezárjuk a visszajelzési hurkot a szélesebb közösség és a MemShrink-en dolgozó fejlesztők között. A korábban tárgyalt eszközök olyan hibákból, amelyeket nem reprodukálhatóként zártunk volna le és felejtettünk volna el, olyan jelentéseket csináltak, amelyeket ki lehetett javítani és ki is javítottunk. A panaszokat, megjegyzéseket és az előrehaladási jelentés blogbejegyzéseinkre adott válaszokat is hibajelentéssé alakítottuk, és megpróbáltuk összegyűjteni a javításukhoz szükséges információkat. Minden hibajelentést osztályoztunk, és prioritást adtunk neki. Arra is törekedtünk, hogy minden hibajelentést kivizsgáljunk, még azokat is, amelyekről megállapítottuk, hogy nem fontos a javításuk. Ez a vizsgálat a bejelentő erőfeszítéseit értékesebbnek érezte, és arra is törekedett, hogy a hiba olyan állapotban maradjon, hogy valaki, akinek több ideje van, később is kijavíthassa. Ezek az intézkedések együttesen erős támogatói bázist építettek ki a közösségben, amely nagyszerű hibajelentésekkel és felbecsülhetetlen értékű tesztelési segítséggel látott el minket.
Következtetések
Visszatekintve a MemShrink projektre: két éve alatt nagy javulást értünk el a Firefox memóriahasználatában. A MemShrink csapata a memóriahasználatot az egyik leggyakoribb felhasználói panaszból a böngésző eladási pontjává tette, és jelentősen javította a felhasználói élményt sok Firefox-felhasználó számára.
Ez eredeti dokumentum köszönetnyilvánítása
Szeretnék köszönetet mondani Justin Lebar-nak, Andrew McCreight-nak, John Schoenick-nek, Johnny Stenback-nek, Jet Villegas-nak, Timothy Nikkel-nek a MemShrink-kel kapcsolatos munkájukért, valamint a többi mérnöknek, akik segítettek a memóriaproblémák javításában. Leginkább Nicholas Nethercote-nak köszönöm, hogy elindította a MemShrink-et, sokat dolgozott a Spidermonkey memóriahasználatának csökkentésén, két éven át vezette a projektet, és még túl sok mindent, amit fel sem tudnék sorolni. Szeretnék köszönetet mondani Jetnek és Andrew-nak is, amiért átnézték ezt a fejezetet.
Forrás:
- https://blog.mozilla.org/nnethercote/2012/02/08/the-benefits-of-reducing-memory-consumption-2/
- https://hacks.mozilla.org/2015/06/performance-testing-firefox-os-with-raptor/
- https://blog.mozilla.org/performance/2020/11/03/dynamic-test-documentation-with-perfdocs/
- https://blog.mozilla.org/performance/2021/11/19/upgrading-page-load-tests-to-use-mitmproxy-7/
- https://firefox-source-docs.mozilla.org/testing/perfdocs/raptor.html
- https://wiki.mozilla.org/Performance/MemShrink
- https://aosabook.org/en/posa/memshrink.html
